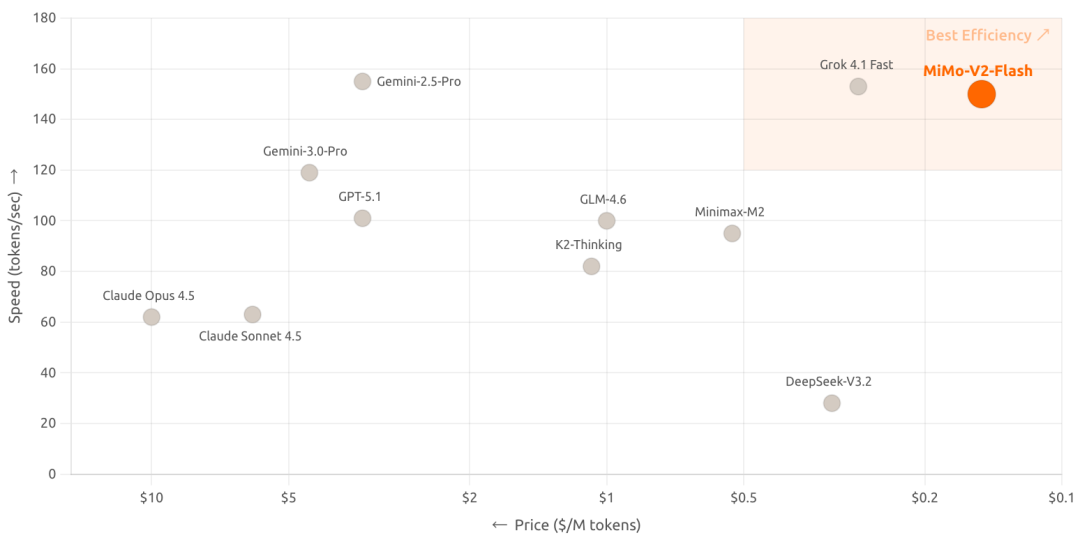
此外,MiMo-V2-Flash 采用 MIT 開源協議,基礎版權重也已經在 Hugging Face 上發布。除去「開源」這一標簽,新模型真正的殺手锏在于架構設計上的激進創新,把推理速度拉到了 150 tokens/秒,成本壓到了每百萬 token 輸入 0.1 美元、輸出 0.3 美元,主打一個超絕性價比。
根據官方體驗頁面信息,MiMo-V2-Flash 還支持深度思考和聯網搜索功能,既能對話聊天,也能在需要實時數據、最新動態或資料核對的場景里派上用場。
基準測試成績顯示,AIME 2025 數學競賽和 GPQA-Diamond 科學知識測試中,MiMo-V2-Flash 都排在開源模型前兩名。編程能力更是亮眼,SWE-bench Verified 得分 73.4%,超越所有開源模型,直逼 GPT-5-High。而這個測試是讓 AI 去修真實世界的軟件 bug,73.4% 的成功率也意味著它能搞定大部分實際編程問題。
在多語言編程基準測試 SWE-Bench Multilingual 里,MiMo-V2-Flash 的解決率為 71.7%。轉看智能體任務,MiMo-V2-Flash 在τ²-Bench 分類得分中,通信類 95.3 分,零售類 79.5 分,航空類 66.0 分,BrowseComp 搜索代理得分 45.4,啟用上下文管理后直接飆到 58.3。
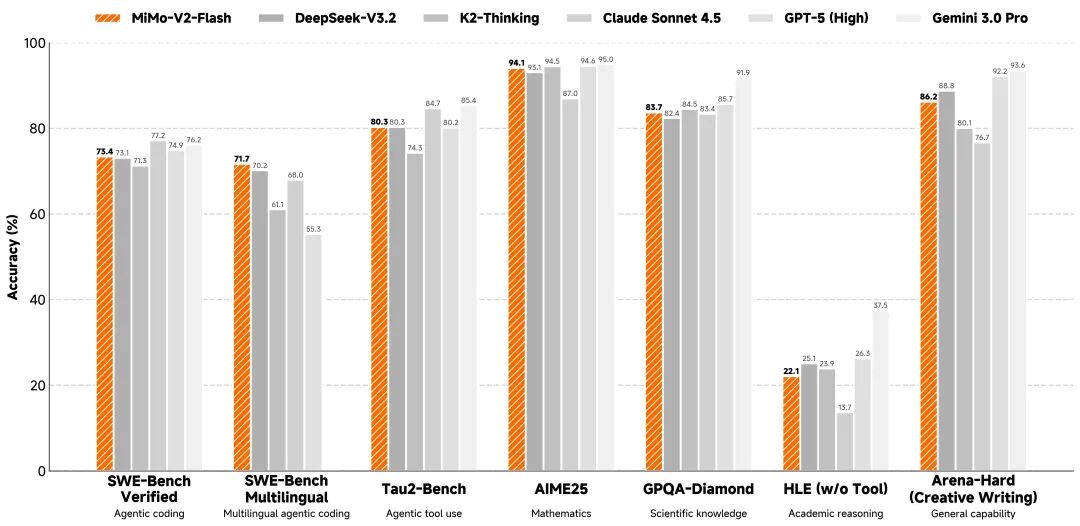
這些數據說明,MiMo-V2-Flash 不僅會寫代碼,還能真正理解復雜任務邏輯,執行多輪智能體交互。
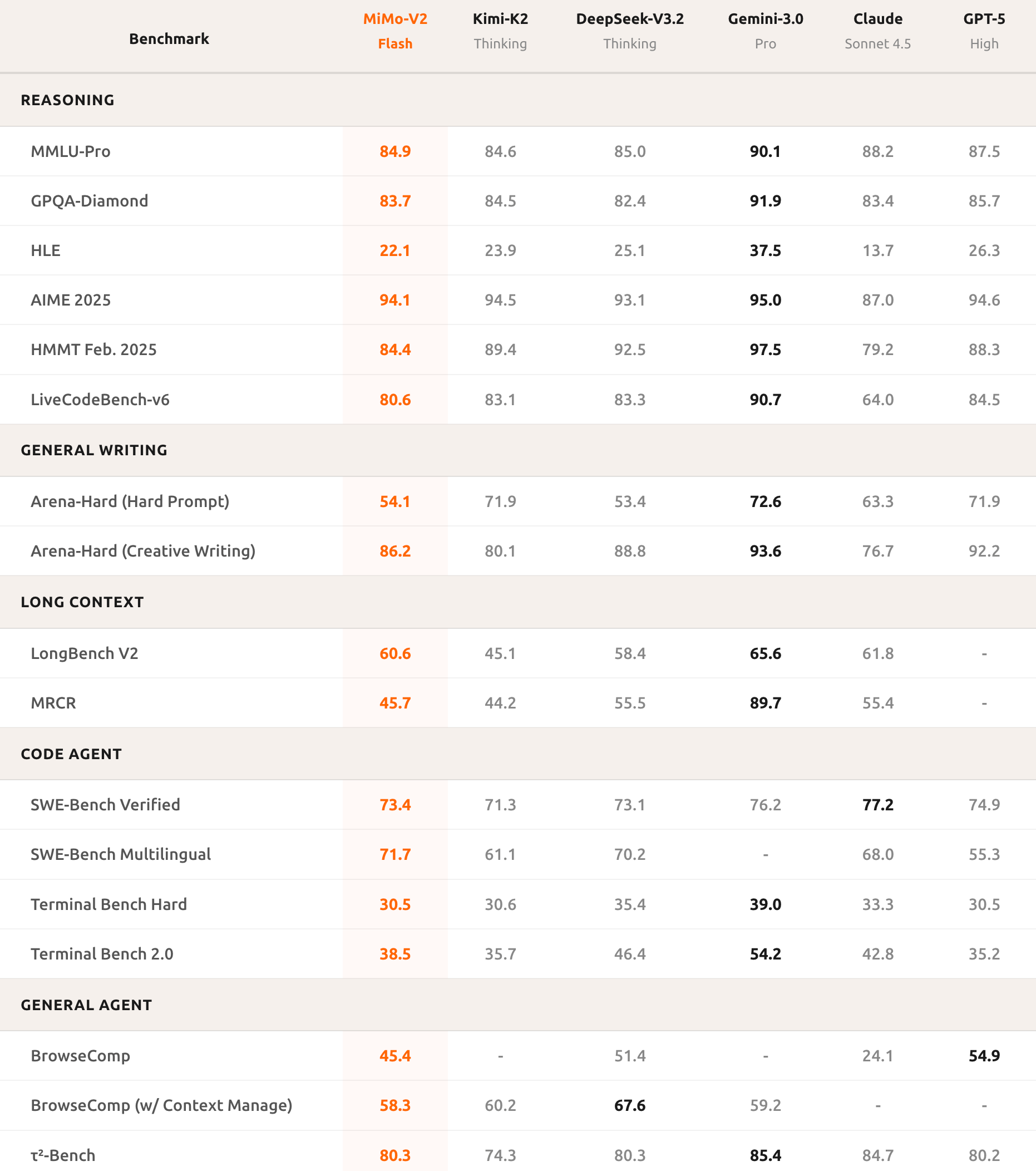
更重要的是,寫作質量也接近頂級閉源模型,這意味著 MiMo-V2-Flash 不只是個工具,還能當個靠譜的日常助手。
MiMo-V2-Flash 在保持長文本性能的同時,還降低了成本,究其原因,離不開兩項核心技術創新。
混合滑動窗口注意力機制:傳統大模型處理長文本時,全局注意力機制會導致計算量二次爆炸,存儲中間結果的 KV 緩存也跟著飆升。
小米這次采用了 5 比 1 的激進比例,5 層滑動窗口注意力搭配 1 層全局注意力交替使用,滑動窗口只看 128 個 token。
這種設計讓 KV 緩存存儲量直接減少了近 6 倍,但長文本能力卻沒打折扣,最長支持 256k 上下文窗口。
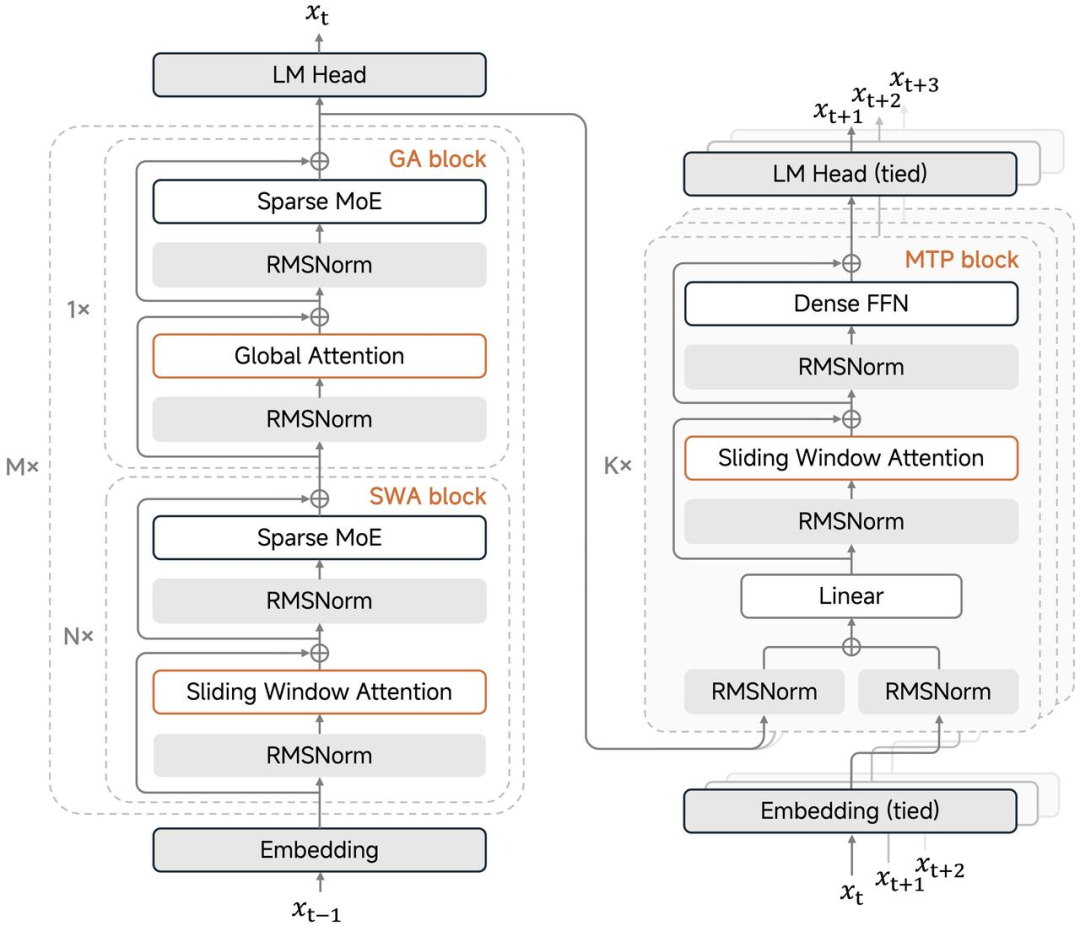
且模型即使在這么激進的窗口設置下,照樣能穩住長文本性能。
對此,羅福莉在社交平臺上特別指出一個反直覺的發現:窗口大小 128 是「最佳甜點值」。實驗證明,盲目擴大窗口(如增至 512)反而會導致性能下降。同時她強調,在實施該機制時,sink values 是維持性能的關鍵,絕不可省略。

另一個黑科技是輕量級多 Token 預測 (MTP)。
傳統模型生成文本時一次只能吐一個 token,就像打字員一個字一個字敲。MiMo-V2-Flash 通過原生集成的 MTP 模塊,能并行預測多個 token,一次性猜出接下來好幾個 token。
實測平均能接受 2.8 到 3.6 個 token,推理速度直接提升 2 到 2.6 倍,不僅在推理時管用,訓練階段也能加速采樣,減少 GPU 空轉,屬于一箭雙雕。
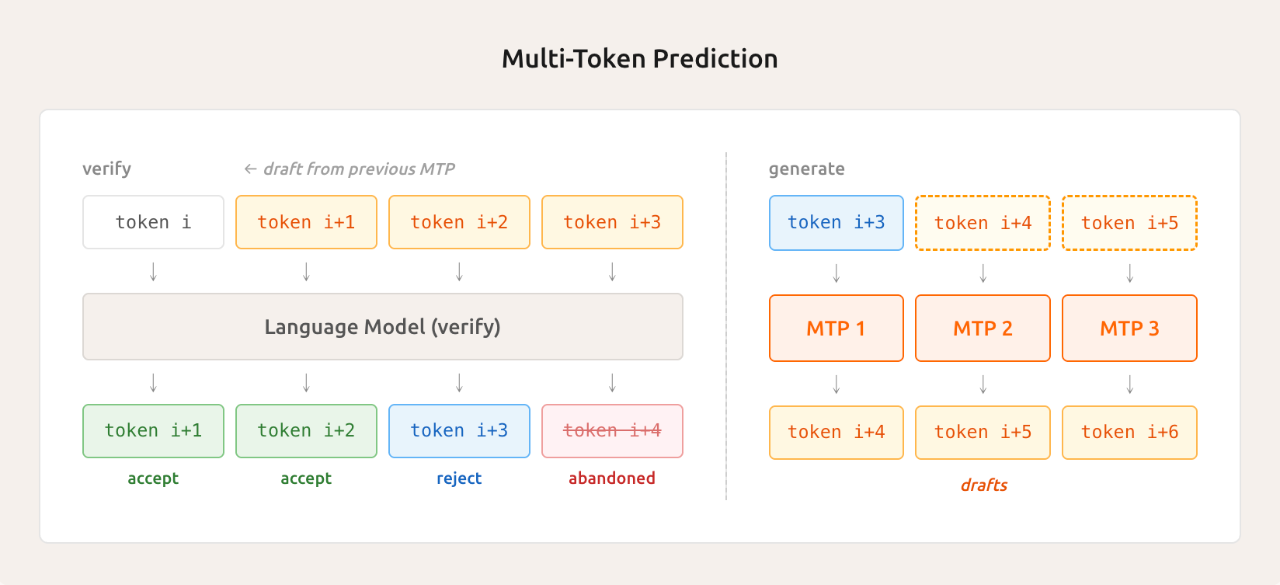
羅福莉提到,在三層 MTP 設置下,他們觀察到平均接受長度超過 3,編碼任務速度提升約 2.5 倍。它有效解決了小批量 On-Policy 強化學習中「長尾樣本」帶來的 GPU 空閑時間浪費問題。
啥叫長尾樣本?就是那些特別難、特別慢的任務,拖著其他任務一起等,GPU 就在那干瞪眼。MTP 把這個問題給解了,極大提高了效率。
不過羅福莉也坦誠,這次因為時間緊迫沒能把 MTP 完整集成進 RL 訓練循環,但它與該流程高度契合。小米已經把三層 MTP 開源了,方便大家在自己的項目中使用與開發。
算力只用 1/50,性能如何不打折?
預訓練階段,新模型使用 FP8 混合精度,在 27 萬億 token 數據上完成訓練,原生支持 32k 序列長度。
FP8 混合精度是一種壓縮數值表示的技術,能在保持精度的同時減少顯存占用和加速訓練。這種訓練方式在業界并不常見,需要對底層框架進行深度優化。
而在后訓練階段,小米整了個大活,提出了多教師在線策略蒸餾 (MOPD)。
傳統的監督微調加強化學習管線,不僅訓練不穩定,算力消耗還賊高。MOPD 的思路是讓學生模型在自己的策略分布上采樣,然后由多個專家教師在每個 token 位置提供密集的獎勵信號。
MOPD Architecture Diagram
通俗點說就是,學生模型自己寫作業,老師在每個字上都給評分,不用等寫完整篇才打分。這樣一來,學生模型能快速從教師那里學到精髓,而且訓練過程穩定得多。
最夸張的是效率提升,MOPD 只需要傳統方法 1/50 的算力,就能讓學生模型達到教師性能峰值。這意味著小米能用更少的資源,更快地迭代模型。
而且 MOPD 支持靈活接入新教師,學生模型成長后還能反過來當教師,形成「教與學」的閉環自我進化。今天的學生,明天的老師,后天又能教出更強的學生,套娃玩法屬實有點東西。
用羅福莉的話來說,他們借鑒 Thinking Machine 的 On-Policy Distillation 方法,將多個強化學習模型進行融合,結果帶來了驚人的效率提升。這為構建一個自我強化循環系統奠定了基礎,學生模型可以逐步進化,最終成為更強的教師模型。
On-Policy Distillation - Thinking Machines Lab
在智能體強化學習擴展上,小米 MiMo-V2-Flash 研究團隊基于真實 GitHub issue 構建了超過 10 萬個可驗證任務,自動化流水線跑在 Kubernetes 集群上,并發能開 10000 多個 Pod,環境部署成功率 70%。
針對網頁開發任務,還專門搞了個多模態驗證器,通過錄制視頻而非靜態截圖來驗證代碼執行結果,直接減少視覺幻覺,確保功能正確。
對于開發者而言,MiMo-V2-Flash 能與 Claude Code、Cursor、Cline 等主流開發環境無縫配合,256k 的超長上下文窗口支持數百輪智能體交互與工具調用。
256k 是什么概念? 大概相當于一本中等篇幅的小說,或者幾十頁技術文檔。這意味著開發者可以把 MiMo-V2-Flash 直接融入現有工作流,不需要額外適配,拿來就用。
小米還把所有推理代碼貢獻給了 SGLang,并在 LMSYS 博客分享了推理優化經驗。
技術報告公開了完整模型細節,模型權重 (包括 MiMo-V2-Flash-Base) 在 Hugging Face 上以 MIT 許可協議發布。這種全面開源的態度,在國內大廠里屬實少見。
目前 MiMo-V2-Flash 已經在 API Platform 限時免費開放,開發者可以直接上手體驗。

文章內容僅供閱讀,不構成投資建議,請謹慎對待。投資者據此操作,風險自擔。
海報生成中...

海藝AI的模型系統在國際市場上廣受好評,目前站內累計模型數超過80萬個,涵蓋寫實、二次元、插畫、設計、攝影、風格化圖像等多類型應用場景,基本覆蓋所有主流創作風格。
IDC今日發布的《全球智能家居清潔機器人設備市場季度跟蹤報告,2025年第二季度》顯示,上半年全球智能家居清潔機器人市場出貨1,2萬臺,同比增長33%,顯示出品類強勁的市場需求。




